

In part 1, I started to unpack my workflows and plug-in choices following a question from community member Sean Amann asking if I would be willing to share my plug-in signal chain on my mix bus when mixing audio for broadcast. In part 1, I covered basic speech programs for podcasts and BBC Radio 4. In this part we are going to look at Music based documentaries which present two different challenges.
They usually will have music underscoring the links and interview content, some shows more than others.
The networks they are broadcast on have more severe transmission processing, over which I have no control.
Based on my experience if I mix these kind of programs the same way as I do straight speech programming I have no control as to how they will sound off air after the transmission processing has done its worst. Different networks have different amounts of transmission processing so I adjust the level of processing I add accordingly. The more sever the processing the more I process the audio in my session. The reason is so that the processing has nothing left to do and my program will sit well with the content around it.

Typical Mixer For Music Based Documentary
For these type of situations I have a number stems as you can see from the screen shot above...
Presenters (links)
Speech Stem
Music Stem
Presenter Stem Channel Strip Of Plug-ins
Presenters Links
I process the links from the presenter(s) with the Waves Renaissance Vox plug-in. As we have said elsewhere it is a great levelling compressor that is very simple to set up.
Next comes an EQ module to tweak the sound of the presenter. As with any EQ, this is adjusted to suit the individual and should not be treated as a preset. In addition I don't always get to record the presenters links so again the eq I use may have to deal with issues in the recording.
Finally in the presenter's chain I use Waves Renaissance Bass to beef up the presenter. This helps to make the links stand out and also give the presenter more 'authority'. This then feeds into the Speech Stem.
Speech Stem
This is all the speech elements in the documentary and is made up of the presenter's links, and all the interview content. Because there will be a lot of music underscoring the interview content it is essential that the speech content is a consistent level without felling over processed and the Waves Renaissance Vox is great at doing this.
Music Stem
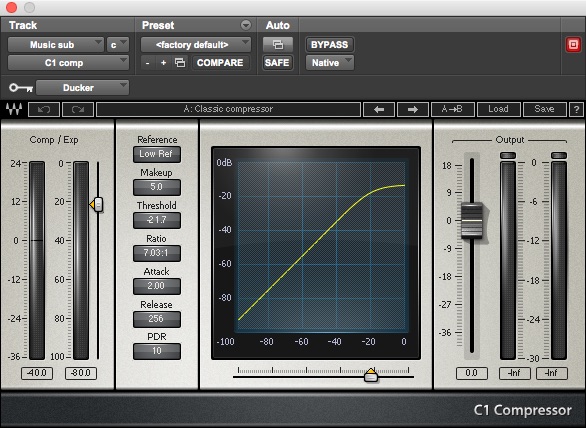
The Waves C1 is acting as a ducker, with a buss fed from the speech stem feeding the external key input. I set this up so it will push the music stem down a little as long as someone is talking. I adjust the Threshold, Ratio, Attack & Release to get it to work nicely. I tend not to get this to do all the work, I will also use volume automation to over ride this when needed.
I also add Waves Renaissance Bass to the music stem to beef up the low end of the music. The Waves Maxxbass and Renn Bass plug-ins are great at helping to get a better low end sound on smaller speakers whilst not destroying the sound on bigger and better playback systems.
Mastering Chain
With the most severe types of transmission processing I will add a multi-band processor, in this case a Waves Linear Phase Multi-band plug-in.

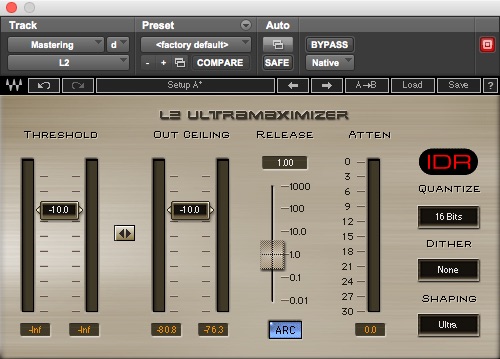
Then finally I have a mastering limiter, which in this case was a Waves L2 which can handle much more gain reduction than the older L1.
In part 3 we will look at the thorny issue of Dither that Sean raised in his question.